
LA ANATOMÍA DE UN PRONÓSTICO ESTADÍSTICO
Cuando se utiliza un modelo estadístico para generar un pronóstico de 12 meses, usted obtiene más que solo doce números. Usted también obtiene una gran cantidad de información sobre cómo se generó el pronóstico, el modelo ajustado a los datos históricos y las diferentes medidas de exactitud del pronóstico. En este artículo, se dividirán y catalogarán los diferentes componentes de un pronóstico estadístico.

La gráfica contiene tres componentes, la demanda histórica, los pronósticos puntuales y los límites de confianza.
Vamos a considerar cada uno a la vez.
DEMANDA HISTÓRICA
La línea verde representa la demanda histórica para un producto sobre una base mensual. Este tipo de conjunto de datos, consiste en observaciones igualmente espaciadas en el tiempo, lo que se conoce como una serie de tiempo. Una técnica de pronóstico que genera un pronóstico basado únicamente en la historia pasada de la demanda se conoce como un método de series de tiempo. Por lo general, los métodos de series de tiempo capturan estructuras tales como los niveles actuales de ventas, tendencias y patrones estacionales, y los extrapola hacia adelante.
PRONÓSTICOS PUNTUALES
La línea roja representa el pronóstico puntual y la línea azul representa los límites de confianza asociados. El futuro es incierto y un modelo de pronóstico estadístico representa la incertidumbre como una distribución probabilística. El pronóstico puntual es la media de la distribución y los límites de confianza describen la propagación de la distribución por encima y por debajo del pronóstico puntual.
El pronóstico puntual puede ser considerado como la mejor estimación del futuro. Es el punto en el que (según el modelo) es igualmente probable que el valor real se caiga por encima o por debajo. Si estamos tratando de estimar los ingresos esperados para nuestro producto, esto es exactamente lo que queremos. Podemos tomar nuestros pronósticos puntuales, y multiplicarlos por el precio de venta promedio para calcular los ingresos esperados.
LÍMITES DE CONFIANZA
Por otra parte, supongamos que queremos saber que cantidad del producto debemos almacenar. Hay costos asociados con tener demasiado inventario (por ejemplo, el almacenamiento, obsolescencia, etc.) y hay costos asociados con no tener el suficiente inventario (por ejemplo, pérdida de ventas, pedidos urgentes, etc.). Aquí es donde los límites de confianza entran en juego. Los límites de confianza son calibrados en porcentajes. En el ejemplo anterior, el límite de confianza superior se establece en 97,5% y el límite de confianza inferior en 2.5%. Esto significa que (según el modelo) la probabilidad de las ventas futuras están en o por debajo del límite de confianza superior 97.5% y la probabilidad de las ventas futuras están en o por debajo del límite de confianza inferior 2.5%. Por lo tanto, si nuestro deseo es mantener un nivel de servicio del 97.5% nosotros podríamos almacenar hasta el límite superior de confianza. Por supuesto, Forecast PRO le permite establecer los porcentajes para los límites de confianza con cualquier valor que desee.
Utilizando los valores de 2.5 y 97.5 para los límites de confianza inferior y superior no es poco común. Si usted piensa acerca de estos valores por un minuto, se dará cuenta de que las posibilidades de las ventas futuras caen entre este límite superior e inferior del 95%. Algunas personas llaman a esta combinación simétrica de configuración de los límites de confianza superior e inferior el 95% de intervalo de confianza.
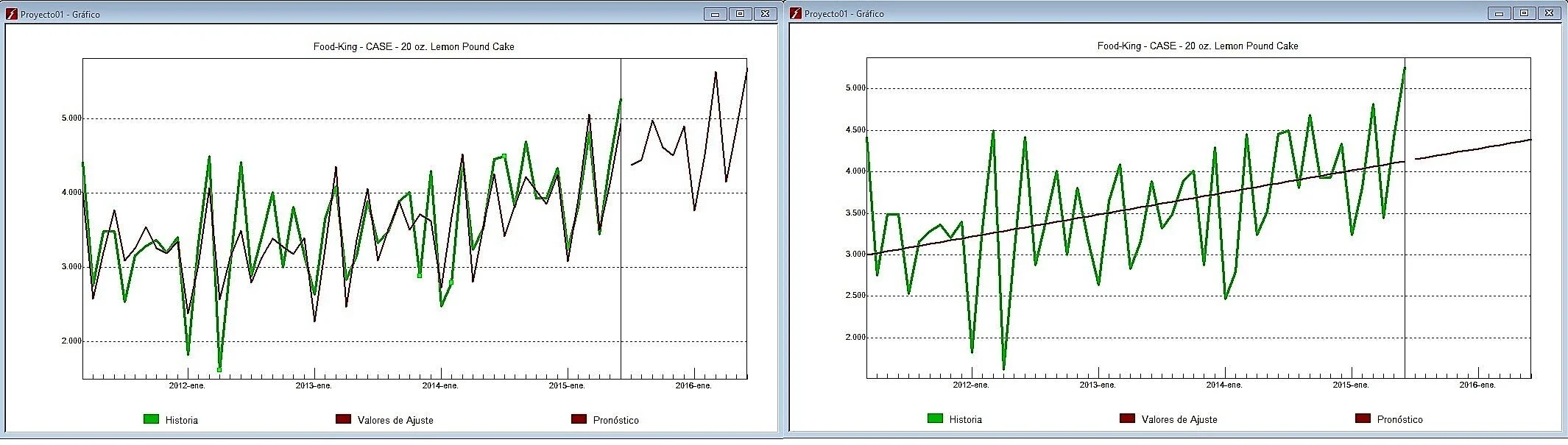
Figura 2
¿Qué modelo es mejor?
Considere los dos gráficos anteriores. El gráfico de la izquierda es igual que la figura 1, con excepción de que hemos agregado la funcionalidad de Valores Ajustados.
Los Valores Ajustados muestran cómo el modelo de pronóstico “rastrea” la historia y puede dar una idea de lo bien que el modelo captura la estructura de los datos.
Considere el gráfico de la derecha. Aquí estamos utilizando la mejor línea de ajuste para pronosticar las ventas del producto. Como ustedes recordarán, la ecuación de una línea recta es Y=mX + b, donde m es la pendiente de la recta, X es el tiempo y b es la intersección. Una vez que hemos seleccionado m y b, esta ecuación se puede utilizar no sólo para generar los pronósticos, sino también para ajustar los datos históricos. Aunque las ecuaciones para el modelo de suavización exponencial son más complejas que para una línea recta, el cálculo de los valores ajustados y los pronósticos se llevan a cabo de una manera similar.
Cuando nos preguntamos cuál de los dos modelos de pronóstico representados en la Figura 2 pronostica las ventas del producto con mayor precisión, la respuesta es claramente el modelo de la izquierda (el cual es un modelo de suavización exponencial).
¿Por qué?
Debido a que se ajusta mejor a los datos históricos.
Además de examinar los valores ajustados de forma gráfica, también puede calcular las estadísticas para medir que tan cerca se está de los datos históricos.
GUÍA ESTADÍSTICA DE LA MEDICIÓN DE ERRORES DE PRONÓSTICOS Y CÓMO UTILIZARLOS
Las estadísticas de medición de errores desempeñan un papel fundamental en el seguimiento de la precisión de los pronósticos, seguimiento de las excepciones, y la evaluación comparativa de su proceso de pronóstico. La interpretación de estos datos puede ser complicado, particularmente cuando se trabaja con bajo volumen de datos o cuando se trata de evaluar la precisión a través de múltiples elementos (por ejemplo, SKUs, ubicaciones, clientes, etc.). Este artículo lista las mediciones estadísticas de los errores más comunes, examina los pros y los contras de cada uno de ellos, y discute su capacidad bajo ciertas circunstancias.
El MAPE
El MAPE (Media absoluta del porcentaje de error) mide el tamaño del error en términos porcentuales. Este es calculado como el promedio del error porcentual sin signo, como se muestra en el siguiente ejemplo:
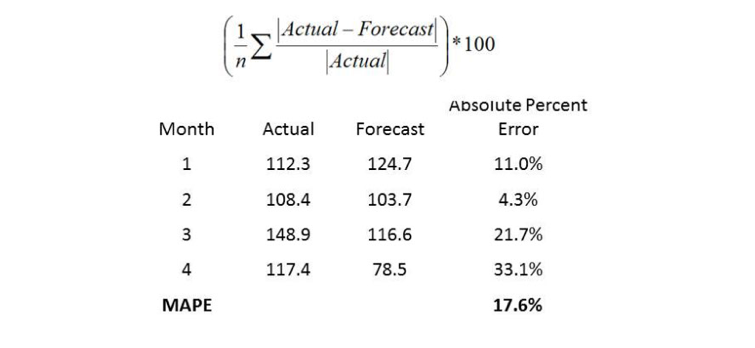
Figura 3
Muchas organizaciones se centran principalmente en el MAPE a la hora de evaluar la exactitud del pronóstico. La mayoría de las personas está cómoda pensando en términos porcentuales, por lo que el MAPE es fácil de interpretar. También se puede transmitir información cuando usted no sabe el volumen de la demanda de dichos ítems.
Por ejemplo, decirle a su gerente “Nos quedamos por debajo del 4%” es más significativo que decir “Nos quedamos por debajo de 3,000 casos”, si su gerente no sabe el volumen de la demanda típica de un ítem.
El MAPE es una escala sensible y no se debe utilizar cuando se trabaja con un volumen de datos bajo. Note que debido a que el “Actual” está en el denominador de la ecuación, el MAPE es indefinido cuando la demanda Actual es cero. Por otra parte, cuando el Actual no es cero, pero es bastante pequeño, el MAPE toma frecuentemente valores extremos. Esta sensibilidad de la escala hace que el MAPE se acerque sin valor como una medida de error para los datos de bajo volumen.
EL MAD
El MAD (Desviación media absoluta) mide el tamaño del error en unidades. Es calculada como el promedio de los errores sin signo, como se muestra en el siguiente ejemplo:
El MAD es una buena medición para usar cuando se analiza el error de un solo ítem. Sin embargo, si usted agrega MADs sobre varios ítems usted necesita tener cuidado acerca de los productos de alto volumen que domina los resultados.
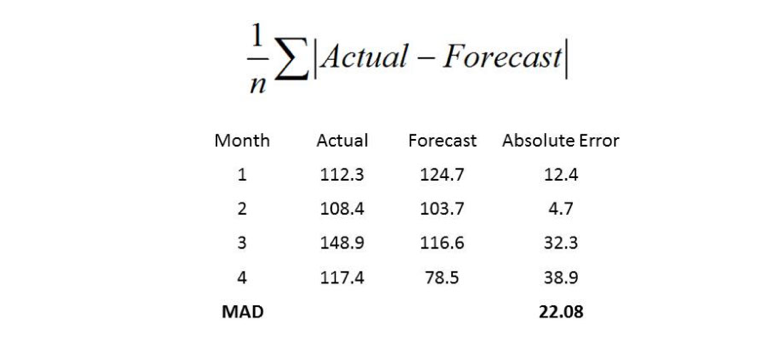
Figura 4
MEDICIÓN ESTADÍSTICA DE ERRORES MENOS COMUNES
El MAPE y el MAD son las mediciones estadísticas de errores más comunes. Hay una serie de estadísticas alternativas en la literatura de pronósticos, muchos de los cuales son variaciones del MAPE y el MAD. Algunos de los más importantes son los siguientes:
RELACIÓN MAD/MEAN
La relación MAD/Media es una alternativa para el MAPE la cual se adapta mejor a los datos intermitentes y de bajo volumen. Como se dijo anteriormente, el porcentaje de error no puede ser calculado cuando el Actual es igual a cero y puede tomar valores extremos, cuando se trata de datos de bajo volumen. Estos problemas se magnifican cuando comienza a promediar el MAPE sobre múltiples series de tiempo. La relación MAD/Media intenta superar este problema dividiendo el MAD por la Media (esencialmente cambiando de escala el error para hacerlo comparable a través de series de tiempo para diferentes escalas. La estadística es calculada exactamente como su nombre lo indica) es simplemente el MAD dividido por la Media.
GMRAE
El GMRAE (Error absoluto de la media geométrica relativa) es usado para medir el desempeño del pronóstico fuera de la muestra. Este es calculado usando el error relativo entre el modelo ingenuo (por ejemplo, el pronóstico del próximo periodo en este periodo actual) y el modelo seleccionado actualmente. Un GMRAE de 0.54 indica que el tamaño del error del modelo actual es sólo el 54% del tamaño del error generado usando el modelo ingenuo para el mismo conjunto de datos. Debido a que el GMRAE se basa en un error relativo, es menos sensible que la escala del MAPE y el MAD.
SMAPE
El SMAPE (Error porcentual de la media absoluta simétrica) es una variación en el MAPE que se calcula utilizando el promedio del valor absoluto del Actual y el valor absoluto del pronóstico en el denominador. Esta estadística se prefiere al MAPE por algunos y se ha usado como una medida de precisión en varios concursos de predicción.
MEDICIÓN DEL ERROR PARA UN ÚNICO ÍTEM VS MEDICIÓN DEL ERROR A TRAVÉS DE MÚLTIPLES ÍTEMS
Medir el error del pronóstico para un único ítem es bastante sencillo. Si está trabajando con un ítem que tiene un volumen de demanda razonable, cualquiera de las mediciones de errores antes mencionados puede ser utilizado, y usted debe seleccionar el que usted y su organización se sienta más cómodo (para muchas organizaciones este puede ser el MAPE o MAD). Si está trabajando con un ítem de bajo volumen, entonces el MAD es una buena opción, mientras que el MAPE y otras estadísticas basadas en porcentajes deber ser evitados.
Calcular la medición estadística del error a través de múltiples ítems puede ser bastante problemático.
Calcular un MAPE agregado es una práctica común. Un problema potencial con este enfoque es que los ítems de menor volumen (que por lo general tienen un MAPE superior) pueden dominar la estadística. Esto generalmente no es deseable. Una solución consiste en separar primero los artículos en diferentes grupos basándose en el volumen (por ejemplo categorización ABC) y luego calcular las estadísticas para cada agrupamiento. Otro enfoque es el de establecer un peso MAPE para cada ítem que refleje la importancia relativa del ítem en la organización (esto es una práctica excelente)
Debido a que el MAD es un error de unidad, calcular un MAD agregado a través de múltiples ítems solo tiene sentido cuando se utilizan unidades comparables. Por ejemplo, si se mide el error en dólares el MAD agregado le indicará el error promedio en dólares.
Resumen
La medición del error del pronóstico puede ser un negocio difícil. El MAPE y el MAD son las estadísticas de medición de errores más comunes; sin embargo, ambos pueden ser engañosos bajo ciertas circunstancias. El MAPE es la escala sensible y debe ser tomado con cuidado cuando usa el MAPE con ítems de bajo volumen. Todas las estadísticas de medición de error pueden ser problemáticos cuando se suman múltiples ítems, y como pronosticador es necesario pensar cuidadosamente a través de su enfoque a la hora de hacerlo.